Point Pattern Analysis I
GEOG 4/597: Advanced Spatial Quantitative
Analysis, Winter 2023
Jackson Voelkel | Portland State
University
Conceptual Framework
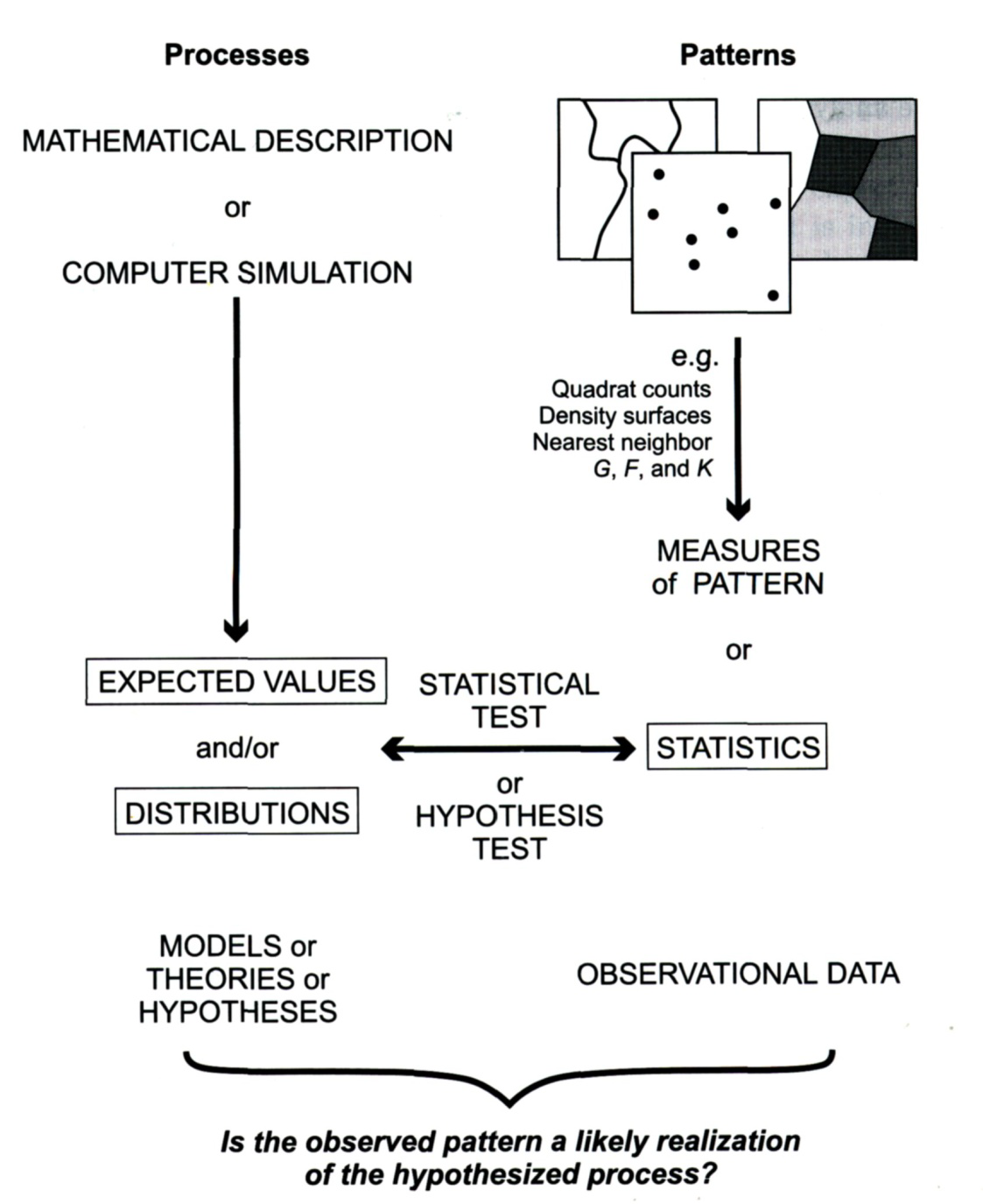
- A measure describing a point pattern can be predicted for a particular process
- Many measures for point patterns exist…
First & Second Order Variation
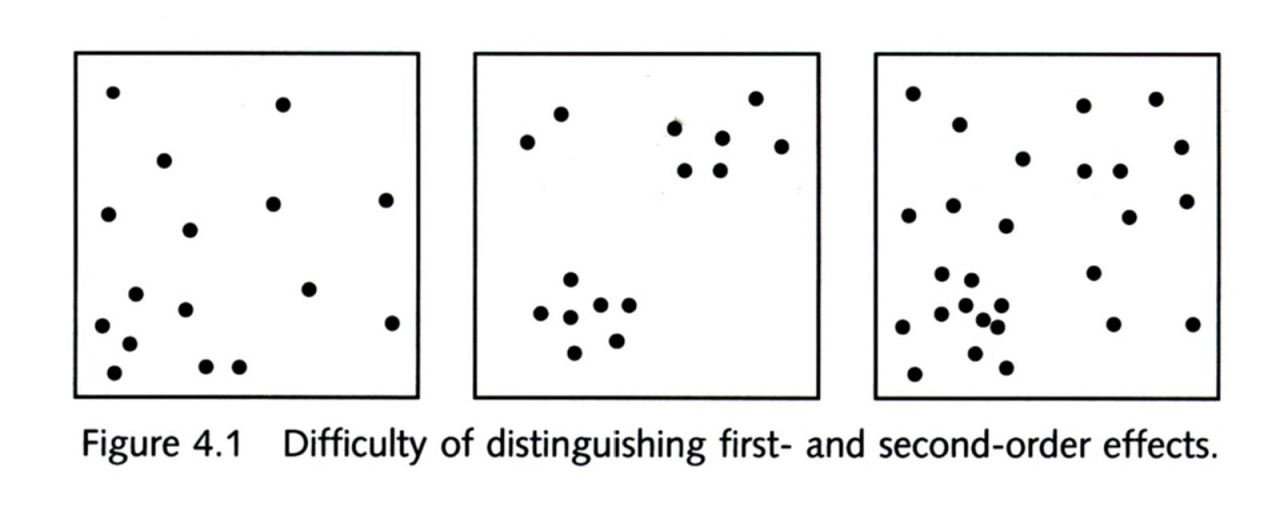
- First order variation is characterized by variation in point pattern density or intensity
- Second order variation is characterized by variation in the distances between events
U.S. Mean Center of Population
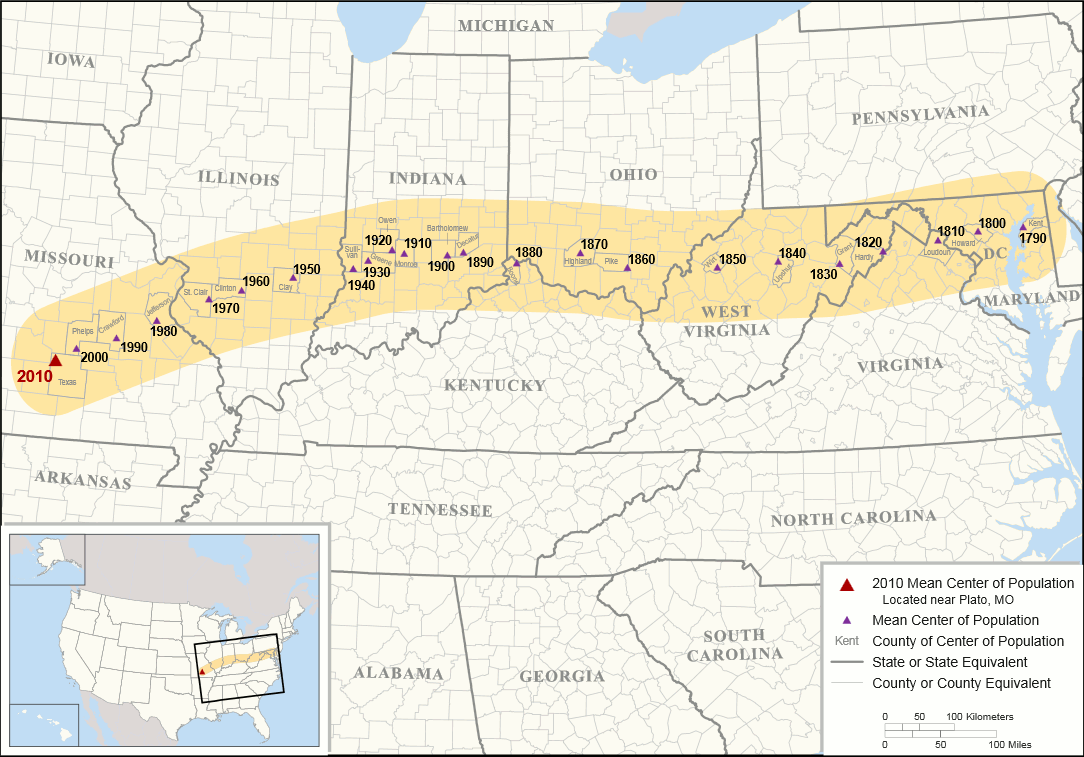
http://maptd.com/2010-united-states-mean-centre-of-population/

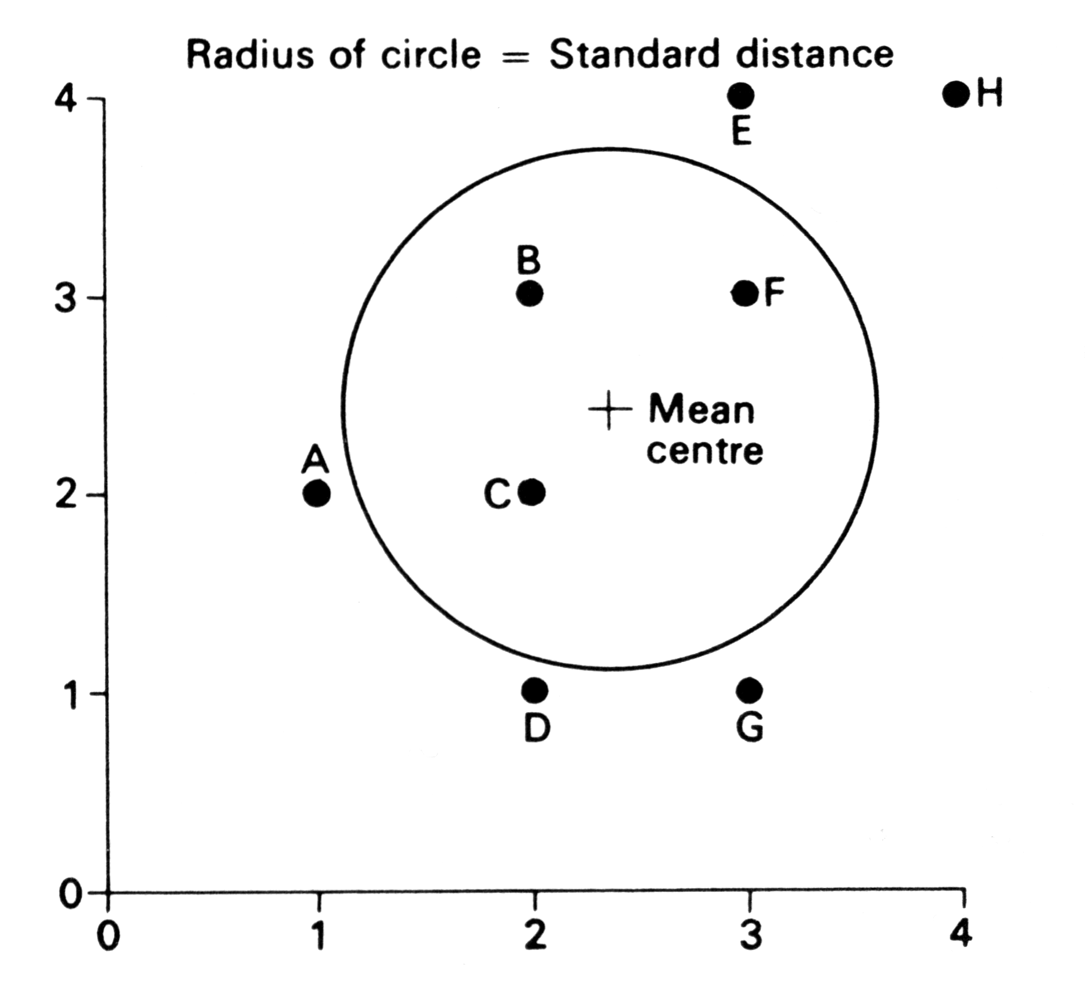
Standard Distance Graph
Describing Poing Patterns - Density-based
Quadrat analysis

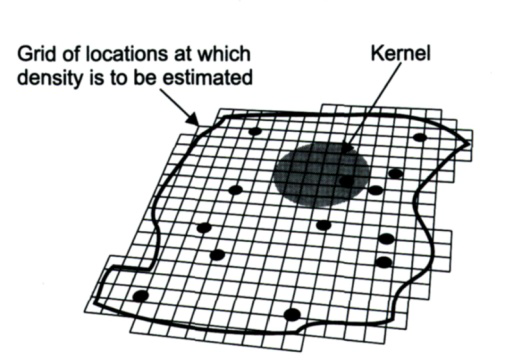
Kernel density estimation
Describing Poing Patterns - Distance-based
Nearest neighbor analysis
Ripley’s K function

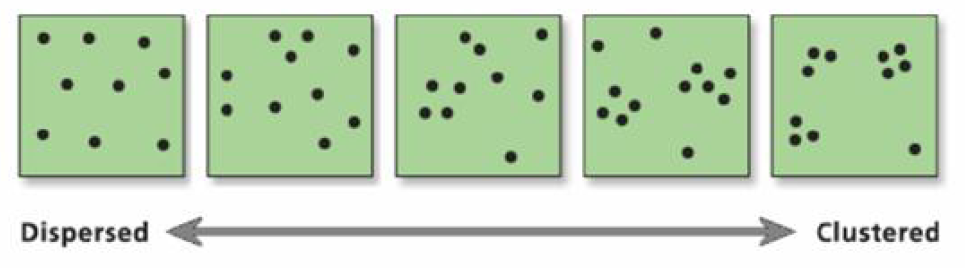
Distribution Examples

Quadrat Sampling
Random Placement with Hexagonal Quadrats

Completed Coverage with Regular Quadrats

Same results… different pattern

So what do we do?
An Alternative

- Nearest Neighbor
- Higher-ordered neighborhood statistics
KDE Example
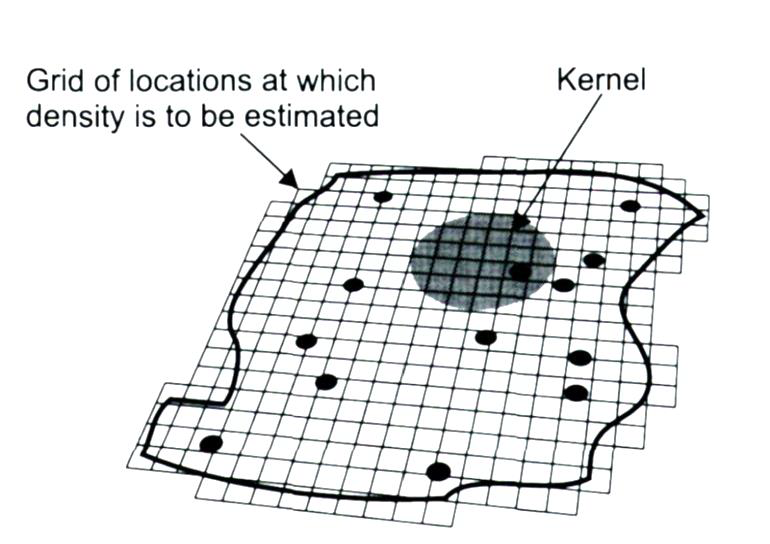
- place grid over study area
- calculate density as \(KDE = \frac{n_i}{a_i}\) (where \(n_i\) = count within kernel; \(a_i\) = kernel area)
KDE Example
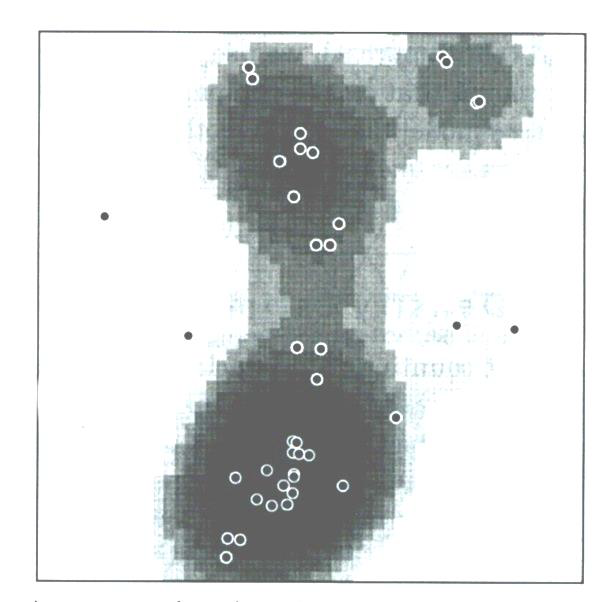
Typical output surface from KDE, and its original point pattern